I researched speaker embeddings so your agent does not have to start cold
I just did a pretty deep research pass on speaker embeddings for Transcripted.
The problem was simple from the outside: Transcripted could label speakers pretty well on clean audio, but the labels got messy on the recordings people actually care about, like Zoom calls and phone calls.
Two different people would get merged into one speaker. Or one person would get split into multiple speakers. Either way, the transcript stopped feeling trustworthy.
At first, this looked like a settings problem. Maybe the matching threshold was wrong. Maybe the clustering needed tuning. Maybe we needed shorter segments. We tried those paths, and they did not really fix it.
The real issue was deeper: the speaker embedding model itself was not holding up under compression. Once the audio got squeezed by Zoom-style or phone-style codecs, the voiceprints for different people started drifting too close together. After that happens, no downstream knob can fully save you.
So we ran a model bake-off. Same audio. Same diarization segments. Same matching pipeline. Only the speaker embedding model changed.
The useful lesson was not just “model X scored better.” The useful lesson was this:
If you are shipping speaker ID on-device, accuracy is not enough. The model also has to survive conversion and produce the same embeddings on the device runtime.
One of the strongest models in the test, CAM++, looked good on accuracy and completely failed the on-device parity check. It converted, it ran, and the output was basically unrelated to the original PyTorch model. ERes2Net was in the same accuracy band and converted cleanly.
So below is the agent article I wish I had been able to hand to my own agents at the start. If you are working on a similar speaker-labeling problem, you can copy this into your agent context and point them at it. It gives them the problem shape, the failed paths, the test design, the model results, and the main lesson: do not trust leaderboard accuracy until you have proven the model works where you actually need to run it.
Want to hand this to your own agent?
Agent article: Your speaker model’s EER doesn’t matter if it can’t run on the device
TL;DR. We build Transcripted, a macOS app that turns recordings into speaker-labeled transcripts. Speaker labels were smearing together on compressed audio: Zoom and phone calls. The obvious fixes, like lowering the match threshold, smarter clustering, and finer segmentation, all failed. The real cause was the voiceprint model itself: under compression, it stops keeping different people apart. So we ran a controlled bake-off of eight embedding models, holding everything else fixed. Several roughly halved the error on our AMI benchmark. But the accuracy co-winner, CAM++, could not be converted to run correctly on Apple’s Neural Engine. Its on-device output is essentially unrelated to the original. The model we recommend, ERes2Net, sits in the same accuracy band on our benchmark and is the one that converts with verified, near-exact on-device parity. The lesson: for on-device speaker ID, conversion fidelity is a first-class axis, not a footnote.

The bug: one voice becomes two people — or two people become one
The bug that started this investigation looks simple from the outside: two different people get merged into a single speaker. You read the transcript and “Alice” is somehow saying things Bob said. It gets worse on exactly the recordings people care about most — Zoom and phone calls — where the audio has been squeezed through a codec (a compression scheme that throws away detail to save bandwidth). On clean, in-room audio the app does okay. Pipe the same voices through a phone line and the labels smear together.
That asymmetry is the tell. Nothing about who is talking changed between the clean recording and the compressed one — only the audio quality did. So whatever is failing must be something that compression damages. Our job was to find that something, and then decide what to do about it.
How a speaker label gets made — and where the weight sits
Producing a speaker label is two steps. First the diarizer answers “who spoke when” — it chops the audio into segments and groups the ones that sound like the same person. (We use PyAnnote segmentation plus VBx clustering, a method for grouping segments by voice.) Second the matcher answers “have I heard this voice before?” — it turns each voice into a voiceprint (an embedding, a list of numbers meant to be close for the same person and far apart for different people) and compares it against known speakers using cosine similarity against a 0.60 threshold. The voiceprints come from a WeSpeaker neural net running on-device on the Apple Neural Engine.
The voiceprint is the load-bearing part. If two people’s voiceprints land close together, no amount of clever grouping downstream can pull them apart — the evidence the rest of the pipeline relies on is already corrupted. So one question organized everything: is the bug in the knobs or the representation? Is it a tuning problem — the threshold, the clustering settings, the segmentation — that we can dial our way out of? Or is the voiceprint itself failing to keep different people apart once the audio is compressed? Those two answers lead to completely different fixes, so we had to know which one we were looking at.
For on-device speaker ID, the decider turns out to be two axes the accuracy leaderboards ignore: how well a model survives audio compression, and whether it survives conversion to the device runtime at all. A model can win on raw accuracy and lose both — and as we’ll see, the one that did win accuracy lost exactly there.
Act I — the obvious fixes, and why they failed
When same-voice recognition fell apart on compressed audio, the first instinct was to reach for the knob we already had: the match threshold. Our matcher calls two voiceprints the same person when their cosine similarity clears 0.60. The obvious move on degraded audio: lower that bar so the matcher stops missing real matches.
It made things worse. Lowering the threshold didn’t recover lost speakers; it fused different ones together.
Here is the least intuitive finding of this act. Compression doesn’t just blur each voiceprint — it pulls different speakers’ voiceprints toward each other. We measured this without picking any threshold, using cross-call AUC (=threshold-free separability: how well same-voice pairs out-rank different-voice pairs by cosine similarity; 1.0 is perfect, 0.5 is a coin flip).
On our AMI benchmark, the raw separation between same and different pairs collapsed as the codec got harsher: clean 0.544 → opus12k 0.421 → opus8k 0.287. The different-speaker band rose from roughly 0.28 to ~0.60 on opus8k — meaning two strangers now score about as high as a genuine match.
No threshold can cleanly split distributions that overlap that much. Lowering it just hands the matcher more false merges.
So we tried three more knobs, and all three tied the baseline:
- Mean-centering the embeddings (subtracting the average voiceprint).
- Smarter clustering — including oracle-k, where we told the algorithm the true number of speakers in advance. Even that gift didn’t help.
- Finer segmentation — cutting the audio into shorter pieces before embedding.
The near-miss is the cautionary tale. Mean-centering looked decisive on the embedding-band metric: on opus8k it restored same-vs-different raw separation from about 0.29 to ~0.77. By that number alone, we’d solved it. But run end-to-end through the real matcher, it changed nothing — it simply traded one error for another, converting merge errors (different people lumped together) into split errors (one person scattered across several identities). The net was a wash.
The lesson is worth stating plainly: a metric that improves in isolation is a hypothesis, not a result. An intermediate signal can look transformed while the thing users actually experience stays flat. The only honest test is end-to-end.
Which points to the conclusion this investigation kept circling back to: the problem isn’t the knobs. It’s the embedding model. When the voiceprints themselves stop separating speakers under compression, no amount of threshold-tuning, re-centering, or re-clustering downstream can recover information the model never preserved.
Act II — the bake-off
The first act taught us a hard lesson: no knob on our current voiceprint saved us. So we asked a blunter question — what if the voiceprint itself is the problem? To answer it fairly, we ran a controlled swap.
The method: hold everything fixed, change only the embedding
We took the exact same diarization segments — the same “who spoke when” boundaries our pipeline already produces — and re-extracted the voiceprint for each segment using eight different models. Same audio, same cuts, same downstream matcher; only the embedding model changes. We did this across a codec sweep, from clean audio down through Opus (24k to 8k) to G.711 mu-law 8k (a telephone-grade codec). Because nothing else moves, any difference we see is attributable to the embedding alone. This is a controlled comparison, not a system rebuild.
The metrics, and why these
We measured two things. Within a meeting: coverage (fraction of true speakers recovered, higher better) and DER (=diarization error rate, the fraction of audio mislabeled by speaker; lower is better). Across meetings: cross-call AUC, defined above.
AUC matters because it is immune to a model’s scale. Some models — especially self-supervised ones like WavLM — are anisotropic (=they cram every voiceprint into a narrow cone, so even different speakers score a high cosine similarity). Raw separation looks tiny, but the ranking of pairs can still be perfect. A threshold-based metric would unfairly punish such a model for its geometry; AUC judges only whether same-voice pairs out-rank different-voice pairs. That is the fair test of discriminative power.
The negative control
We included x-vector, an older embedding, as a deliberate negative control. It loses on every arm (DER ~0.51 / ~0.50 / ~0.49, the worst of the field everywhere). This rules out the lazy conclusion that any swap helps — it doesn’t. The win, where it exists, comes from a genuinely stronger discriminative model.
Results
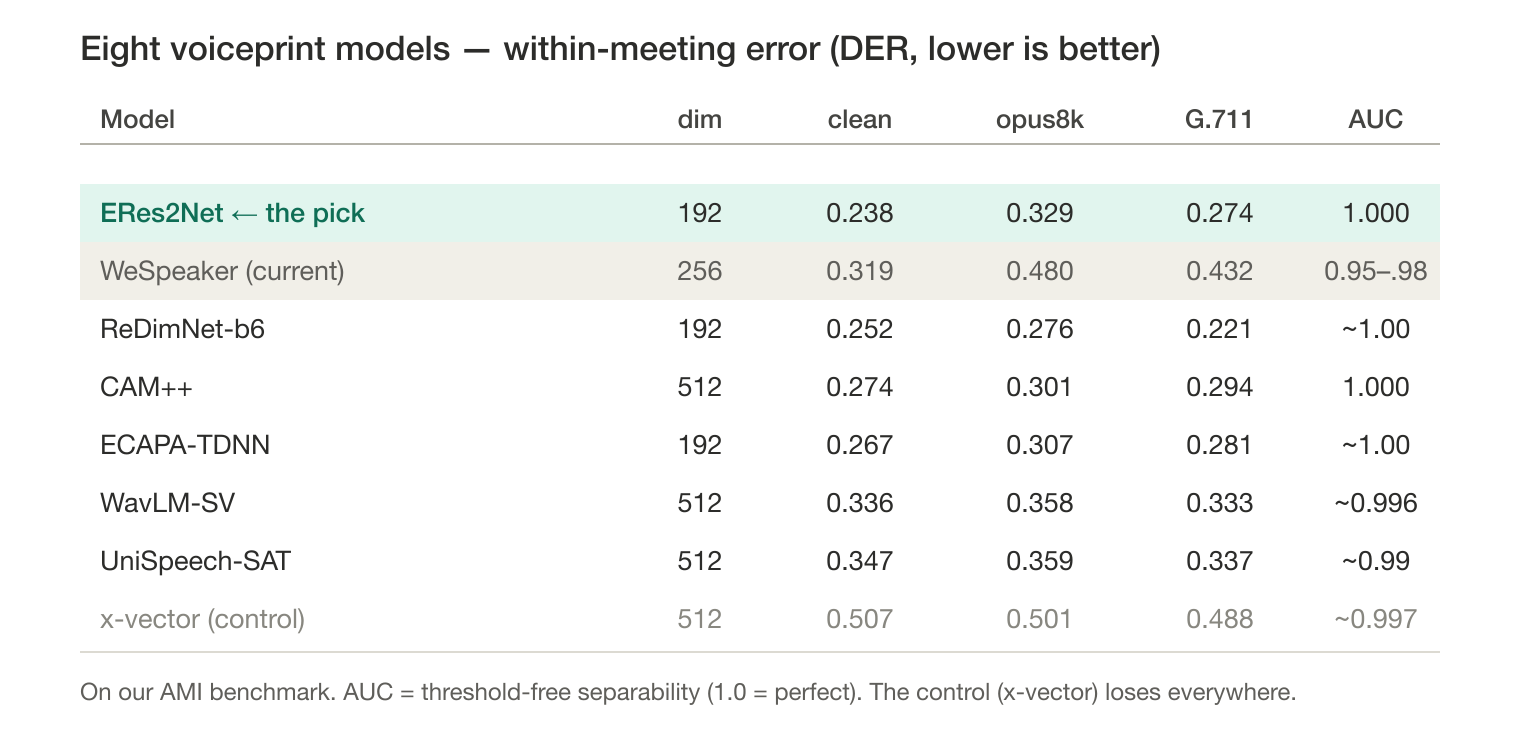
| Model | dim | DER clean | DER opus8k | DER g711u | cross-call AUC |
|---|---|---|---|---|---|
| WeSpeaker (current) | 256 | 0.319 | 0.480 | 0.432 | 0.979 / 0.948 / 0.970 |
| ECAPA-TDNN | 192 | 0.267 | 0.307 | 0.281 | ~1.000 |
| ReDimNet-b6 | 192 | 0.252 | 0.276 | 0.221 | ~1.000 |
| CAM++ | 512 | 0.274 | 0.301 | 0.294 | 1.000 |
| ERes2Net | 192 | 0.238 | 0.329 | 0.274 | 1.000 |
| WavLM-SV (anisotropic) | 512 | 0.336 | 0.358 | 0.333 | ~0.996 |
| x-vector (control) | 512 | ~0.51 | ~0.50 | ~0.49 | — |
(AUC columns are clean / opus8k / g711u, matching the DER columns.)
The pattern is clear, on our AMI benchmark. A stronger discriminative model roughly halves error on compressed audio — opus8k falls from WeSpeaker’s 0.480 to the ~0.28–0.30 range, g711u from 0.432 to ~0.22–0.29 — and stays flat where WeSpeaker collapses. Cross-call AUC is near-perfect for the discriminative leaders, meaning they keep different voices separable even after compression mangles the audio.
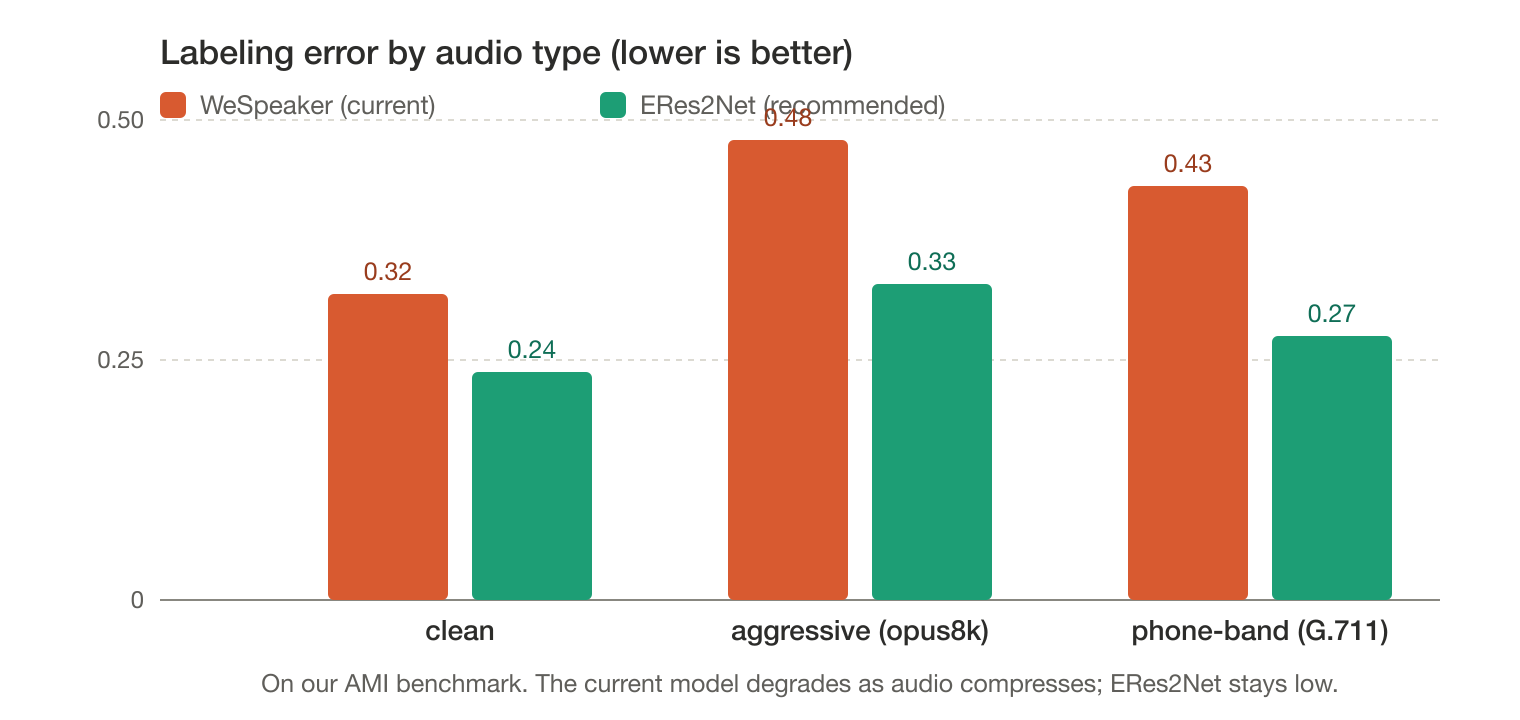
The deeper finding
One residual limit is not the embedding: the within-meeting floor is set by the diarizer, not the matcher. We tested this directly. Smarter clustering — even oracle-k, where we hand it the true speaker count — only ties the app, and the 0.88 same-voice consolidation knob is inert (toggling it changes nothing). Pure single-speaker segments still merge. That is under-segmentation, a diarizer property, not a clustering or threshold lever. A better embedding fixes the cross-call identity problem; the within-meeting ceiling waits on the diarizer.
Act III — the twist: accuracy ≠ shippable
By the end of the bake-off, we had a four-way tie. ERes2Net, ReDimNet, CAM++, and ECAPA-TDNN all roughly halve the opus8k error of our current voiceprint model on our AMI benchmark — DER drops from 0.480 to the 0.28–0.30 range, and all four post near-perfect cross-call AUC. On a leaderboard, you could pick any of them. (One honesty note: within that tie, ERes2Net actually wins clean DER outright at 0.238 but is the worst of the four on opus8k at 0.329 — it sits inside the accuracy band, not at the top of every arm. We’ll come back to why we recommend it anyway.)
A leaderboard measures the model in a lab. We have to run it on a phone — specifically, converted to CoreML and executed on Apple’s Neural Engine. So the real decider isn’t accuracy. It’s whether the model survives conversion and still produces the same numbers on-device. We tested that, and it broke the tie.
CAM++ — one of the accuracy co-winners — fails. It converts. It runs. And it emits garbage: the converted model’s voiceprint matches the original PyTorch voiceprint with a cosine similarity of only ~0.23, where we need >0.99. (Cosine ~1.0 means “same vector”; ~0.23 means the on-device model is computing something essentially unrelated.) A model that’s best-in-class on the benchmark and wrong on the device is not shippable.
Here’s the honest part: our first diagnosis was wrong. We blamed float16 precision on the Neural Engine, then blamed CAM++‘s tiny-variance BatchNorm layers (a known source of numerical blow-up). Both guesses were wrong. We proved it by converting at float32 on CPU, where neither factor applies — and the error persisted, identically, in two independent converters (ONNX and CoreML diverged the same way). That’s the fingerprint of an architectural problem, not a precision one: CAM++‘s deep architecture stacks many layers that each re-combine their inputs (dense-concat plus reshape, layer after layer), so a little error accumulates at every step and grows with depth. There is no clean workaround.
ERes2Net, by contrast, converts cleanly. Same-vector parity with the original is cosine 0.99999 at float16 (Neural-Engine eligible) and exactly 1.000000 at float32. The model is 12.76 MB, loads with zero missing weights, and needed exactly one output-neutral one-line patch (swapping a clamp for a ReLU — the change the official exporter makes too). Notably, ERes2Net has even more extreme tiny-variance BatchNorm than CAM++ and still converts perfectly — which confirms the cause was architecture, not weights.
The lesson is one a leaderboard can never teach you: validate the conversion and on-device parity, not the leaderboard. “Has an ONNX export” is not the same as “produces correct outputs on the device you ship.” Of the models that tie on accuracy, only one also passes that second, harder test.
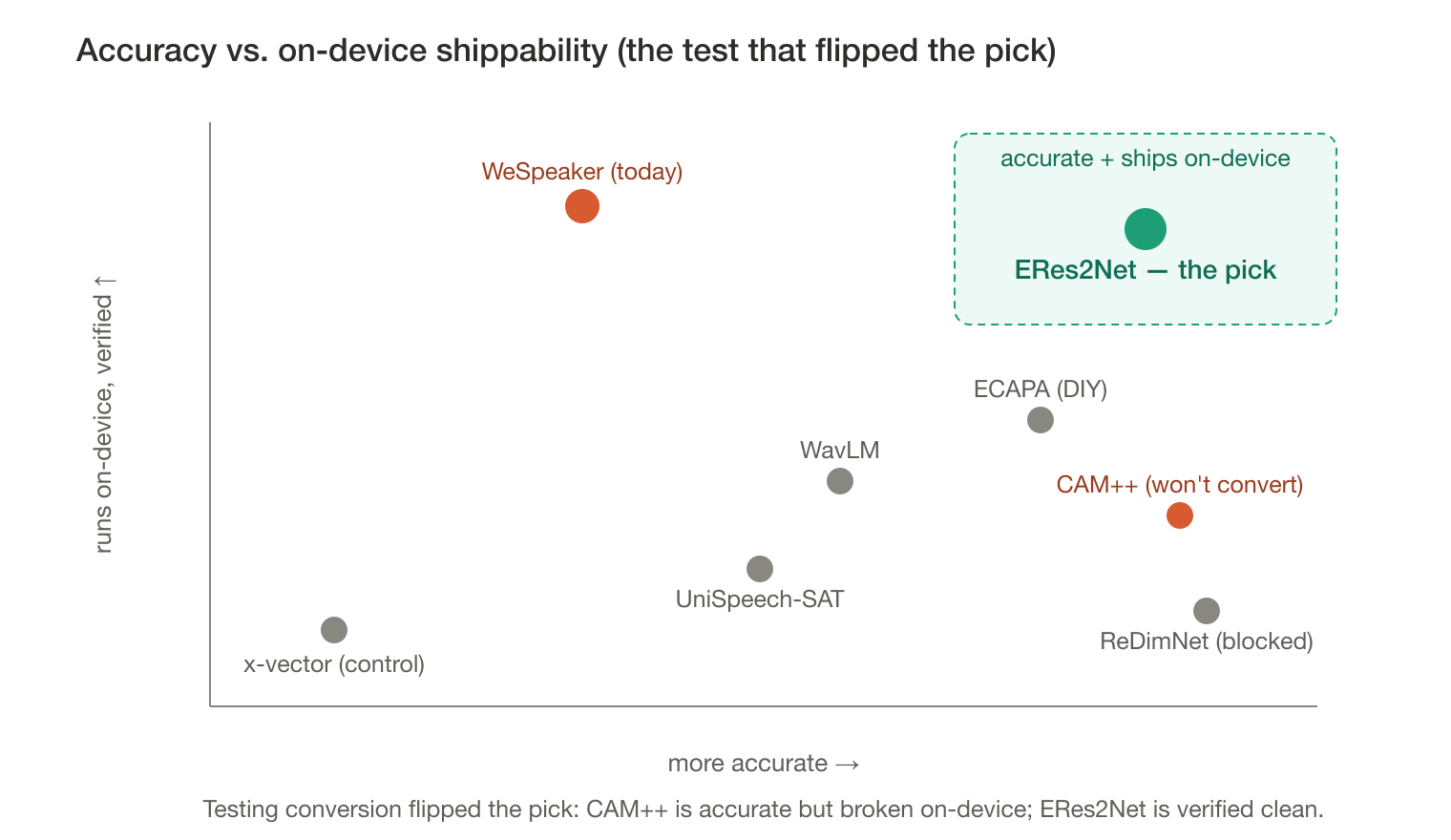
So the recommendation is concrete: ship ERes2Net. We choose it for conversion fidelity — it is within the accuracy tie band on our AMI benchmark (not the per-arm leader on opus8k) and is the one model with a verified, near-exact on-device conversion. Real-Zoom validation hasn’t run yet, so this is a strong internal signal, not a confirmed production gain.
Takeaways for practitioners
We spent a long time turning knobs and the knobs lost. The lessons below are what we’d tell anyone debugging a voice-matching system. (Quick glossary, defined once above and reused here: voiceprint = the numeric embedding of a voice; DER = diarization error rate, lower better; cross-call AUC = threshold-free separability, 1.0 perfect; anisotropy = embeddings crammed into a narrow cone so even different voices score high cosine.)
- Stop tuning knobs; fix the representation. Lowering the match threshold made things worse, not better. Mean-centering, smarter clustering (even oracle-k), and finer segmentation all roughly tied the baseline. Compression was pulling different speakers’ voiceprints together — no threshold can separate points that already overlap. The fix was a better embedding model, not a better setting.
- Test end-to-end, not a proxy. Mean-centering looked decisive: it restored embedding-band separation on the worst codec (opus8k, raw separation ~0.29 → ~0.77). Through the real matcher it did nothing — it just traded merge errors for split errors. A clean proxy metric can move while the thing you actually ship stays flat.
- Use threshold-free, anisotropy-immune metrics. Cross-call AUC let us rank models without picking a threshold first, so a model that crams everything into a narrow cone (WavLM, raw separation ~0.27) couldn’t fake its way to a good score. Raw cosine gaps would have misled us; AUC didn’t.
- Run a negative control. We swapped in x-vector on purpose. It lost on every arm (DER ~0.51 / 0.50 / 0.49, the worst everywhere). That tells us the win isn’t “any swap helps” — it’s specifically the stronger discriminative models.
- Treat conversion and on-device parity as a first-class axis, not a footnote. CAM++ matches the accuracy leaders and is unshippable: its CoreML parity cosine came out at ~0.23 against PyTorch, and the same divergence shows up in ONNX at float32 on CPU, so it’s architectural, not precision. ERes2Net converts at 0.99999 (fp16) to 1.000000 (fp32) parity after one output-neutral line change. Accuracy you can’t run on the Neural Engine is accuracy you can’t ship.
- The deep residual was upstream. The within-meeting 0.88 same-voice consolidation knob looked like the obvious lever, so we toggled it on and off — completely inert (profiles, trapped speakers, DER all unchanged). The real ceiling on within-meeting granularity was the diarizer under-segmenting. A better embedding restores granularity the diarizer alone can’t (on our AMI benchmark, opus8k: ~10 profiles to ~21–32, the upper figure coming from ReDimNet’s run, the lower from CAM++‘s). We’d have wasted days on a knob that does nothing.
Honest limitations
Everything above is on our AMI benchmark, and we want to be clear about what that does and doesn’t buy. AMI is a single corpus: four-party, in-room, far-field meetings. Our compression arms are synthetic — we ran AMI through ffmpeg codecs (Opus, G.711), not real captured Zoom or Meet calls, so the degradation is plausible but not the real thing. The diarizer is one specific proprietary system; the absolute numbers won’t transfer to another stack, though we believe the direction will. On-device latency was inferred from parameter count and model size, not profiled on the Neural Engine. And we have no real-Zoom validation yet, though the tooling is ready.
To make this a peer-reviewed result, we’d want real codec corpora (actual captured calls), a second dataset beyond AMI, and published equal-error-rate (EER) baselines to compare against. Treat this as a strong internal signal, not a published finding.
Reproduce
The recipe is deliberately cheap. Diarize each meeting once, then swap only the embedding model and re-score — you don’t re-run diarization per model, so a full bake-off is fast. Score three things: within-meeting DER, within-meeting coverage (fraction of true speakers recovered), and cross-call AUC on same-vs-different meeting pairs.
The models are all free. ERes2Net and CAM++ come from 3D-Speaker (modelscope; permissive code). ECAPA-TDNN is SpeechBrain (Apache-2.0), a clean DIY fallback. ReDimNet is MIT. WavLM and UniSpeech-SAT are Microsoft via transformers. The model code and weights are free to use; the training-data nuance is separate. VoxCeleb2 is non-commercial for training, but using released weights is the same posture as our already-shipping WeSpeaker, which is itself VoxCeleb-derived — so ERes2Net adds no new licensing risk.
Build the codec arms with ffmpeg: clean, Opus at 24k/16k/12k/8k, and G.711 mu-law 8k. Then add the conversion check as its own gate — convert to CoreML and measure parity cosine against PyTorch, targeting >0.99. That step is what separates a benchmark winner you can’t deploy (CAM++) from something you can actually put on the Neural Engine (ERes2Net).
Takeaways box
- The problem was the representation, not the knobs. Compression pulled different speakers’ voiceprints together; no threshold can split overlapping points.
- Proxy metrics lie; only end-to-end tells the truth. Mean-centering looked like a fix and changed nothing downstream.
- Pick threshold-free, scale-immune metrics. Cross-call AUC ranked models fairly; raw cosine gaps would have misled us.
- Conversion fidelity is a hard gate. CAM++ ties on accuracy and fails on-device (parity ~0.23); ERes2Net ties on accuracy and converts (parity 0.99999–1.000000).
- Ship ERes2Net — within the accuracy band on our AMI benchmark, the only model with verified near-exact on-device parity. Real-Zoom validation is the next step.
- All numbers are on our AMI benchmark with synthetic codecs. Strong internal signal, not a published result.